Test4
Tue 01 July 2025
import pandas as pd
import csv
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
df = pd.read_csv('IMDB Dataset.csv',
quoting=csv.QUOTE_MINIMAL,
on_bad_lines='skip',
encoding='utf-8')
df.head()
| review | sentiment | |
|---|---|---|
| 0 | One of the other reviewers has mentioned that ... | positive |
| 1 | A wonderful little production. <br /><br />The... | positive |
| 2 | I thought this was a wonderful way to spend ti... | positive |
| 3 | Basically there's a family where a little boy ... | negative |
| 4 | Petter Mattei's "Love in the Time of Money" is... | positive |
df.isnull().sum()
review 0
sentiment 0
dtype: int64
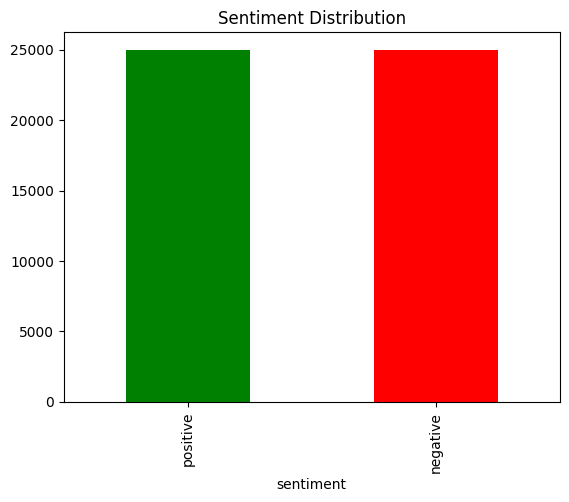
df['sentiment'].value_counts().plot(kind='bar', color=['green', 'red'], title='Sentiment Distribution')
plt.show()
df['sentiment'] = df['sentiment'].map({'positive': 1, 'negative': 0})
df.head()
| review | sentiment | |
|---|---|---|
| 0 | One of the other reviewers has mentioned that ... | 1 |
| 1 | A wonderful little production. <br /><br />The... | 1 |
| 2 | I thought this was a wonderful way to spend ti... | 1 |
| 3 | Basically there's a family where a little boy ... | 0 |
| 4 | Petter Mattei's "Love in the Time of Money" is... | 1 |
X_train, X_test, y_train, y_test = train_test_split(
df['review'], df['sentiment'], test_size=0.2, random_state=42)
vectorizer = TfidfVectorizer(stop_words='english', max_features=10000)
X_train_tfidf = vectorizer.fit_transform(X_train)
X_test_tfidf = vectorizer.transform(X_test)
X_train_tfidf.shape, X_test_tfidf.shape
((40000, 10000), (10000, 10000))
model = LogisticRegression()
model.fit(X_train_tfidf, y_train)
LogisticRegression()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Parameters
| penalty | 'l2' | |
| dual | False | |
| tol | 0.0001 | |
| C | 1.0 | |
| fit_intercept | True | |
| intercept_scaling | 1 | |
| class_weight | None | |
| random_state | None | |
| solver | 'lbfgs' | |
| max_iter | 100 | |
| multi_class | 'deprecated' | |
| verbose | 0 | |
| warm_start | False | |
| n_jobs | None | |
| l1_ratio | None |
y_pred = model.predict(X_test_tfidf)
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
print("\nClassification Report:")
print(classification_report(y_test, y_pred, target_names=["Negative","Positive"]))
Confusion Matrix:
[[4330 631]
[ 459 4580]]
Classification Report:
precision recall f1-score support
Negative 0.90 0.87 0.89 4961
Positive 0.88 0.91 0.89 5039
accuracy 0.89 10000
macro avg 0.89 0.89 0.89 10000
weighted avg 0.89 0.89 0.89 10000
Score: 10
Category: basics